Note that I made a grave error of thinking before writing this article: I forgot the copy-on-write page sharing of modern Unices. I added two paragraphs to this article that should clarify the point. Thanks for your comment, Alex.
Please note that I do not want to critizize Jason here. I am simply picking up this point from his presentation as a motivation of a topic that I wanted to write about since the issue with Ruby and threads occured. Also note that I actually like Ruby a lot and I am using it in almost all of my projects either for support scripts or as the main programming language: I am not anti-Ruby.
Today, the Riding Rails weblog linked to the slides of Jason Hoffman's tutorial Scaling a Rails Application from the Bottom Up in one of their entries.
While I do not want to doubt his expertise on scaling applications — he is the successful founder of Joyent, TextDrive and Strongspace — I stumbled over slide 115 of his tutorial which says
- I like that Ruby is process-based
- I actually don’t think it should ever be threaded
- I think it should focus on being as asynchronousand event-based on a per process basis
- I think it should be loosely coupled
- What does a “VM” do then: it manages LWPs
- This is erlang versus java
I have not attented his tutorial and thus I might misunderstand him. I might not be proficient enough in system and computer architecture. Nevertheless, I am wondering about the scalability of pure processes. There was a quite a discussion about Ruby and real kernel multithreading some time ago, but I did not read an article covering the same aspect that is discussed here: Memory Bus Saturation.
Thread, Process and Address Space
Let's recap the textbook definitions of threads, processes and adress spaces. Note that they do not necessarily map to what vendors call them or are consistent over all text books.
- A thread is pure activity, i.e. the information about the current position of execution (instruction pointer), the registers and the current stack.
- An address space is a range of addressable memory that is only accessible by activities that are allowed to read/write from it.
- A process consists of an address space and one or multiple threads.
OK, what does this mean? Each program that you run on your computer runs in its own address space if you are using a modern operating system, for example your web browser and your email client. Both applications (processes) appear to execute concurrently, i.e. you can download a web page and send an email at the same time. Even within each process, you can have multiple activities — threads. For example, your browser might download two images from a web site at the same time.
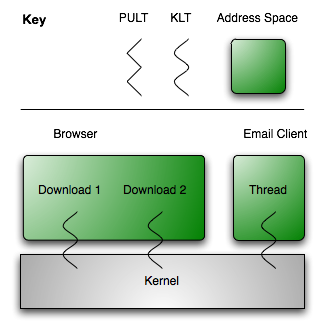
Your operating system executes the applications seemingly concurrently by using time slicing, i.e. assigning each process/task to the CPU for a short time and then assinging the next one.
Where is the real difference between processes and threads? Well, two threads within the same address space can access the same memory address at the same time. For example, both of the threads downloading an image can access the list of images for a website document.
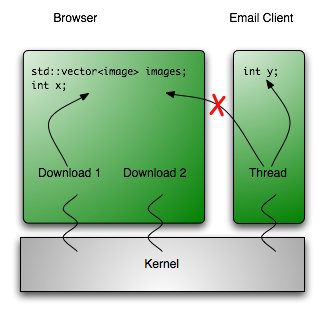
The thread from your email applications cannot access this list. If the web browser and email client want to communicate, the operating system has to provide means for this. Communication could be done through files, pipes, sockets or message passing within the operating system.
User and Kernel Level Threads
Whee, that were a lot of new terms, eh? I have two other ones for you: kernel level threads and pure user level threads.

A kernel level thread (KLT) is a thread that the kernel is aware of, i.e. the kernel can decide which KLT will be schedule (assigned ot the CPU). Pure user level threads (PULTs) are not known to the kernel: One or more PULTs may run on top of a KLT and the kernel can only schedule the KLT. The decision which of the PULTs is scheduled is left to the user level scheduler in your application.
There are some tradeoffs between PULTs and KLTs and there are even hybrid models but the following problem remains: The kernel can only schedule KLTs to run on a given CPU. If you have more than one CPU/core then the kernel can schedule two KLTs to run concurrently. For example you could decompress two JPEGs at the same time in your web browser if you have two cores on your CPU.
Ruby only offers PULTs. What does this mean? This means that you cannot have one Ruby process with two threads running at the same time. You cannot, for example, let a Rails process generate two differently sizted thumbnails of an uploaded image at the same time. You cannot answer more than one request at the same time without stopping the other thread. You cannot do numerical computations on more than one core at the same time.
Ruby And 64 Core CPUs
So, we are coming closer to the problem that I see with Ruby and the upcoming 64+ core CPUs that DHH would welcome ``any day'' (so would most of us, right?). Try the following: Start the Ruby interpreter and a Rails console with ./script/console. The plain Ruby interpreter uses 1.2MiB and the Rails console session uses 28.42MiB on my Os X box; your mileage may vary.
I have not done any measurements but consider the following: Each of your Rails process needs 1.2MiB of memory for the interpreter and then more propably more than 20MiB of memory for your application instance. Some of this memory will be actively used in the inner loops of your program, let's make a conservative guess and say that each of your processes needs 0.5MiB of the address space most of the time. If you have a 64 core CPU then you need 32MiB of L2/L3 cache to access the memory quickly.
A typical L2 Cache on a Core 2 CPU with two cores is 4MiB of size. We could do some simple calculations and get that by the time, we have this 64 core processor, our L2 cache will have a size of 128MiB. After all, Wikipedia tells us that by 2007/2008 we will have 6MiB of L2 cache for two cores.
However: First, there are some physical limitations to the size of a cache hierarchy since electricity can only travel that fast. Second, as good engineers, we should consider whether we could cut down the memory requirements with sufficiently little work.
How would a multithreaded Ruby help to save memory? Well, the Rails console session used all of its memory by declaring classes and doing some initialization work. Most of this memory could be shared by multiple threads since you normally do not modify your classes on the fly in production systems. Your interpreter could be shared, too. By the estimates above, we could save more than 31MiB of cache for all the stack data we want.
Note that we could also save this memory with processes when forking at the correct time: When a process creates a child process, old Unices copied the whole address space. This is no longer the case: Modern Unices allow read access to the old address space from the new address space. When a memory location is written to by any process, the page will be copied into the new process' address space. Thus, if our Ruby/Rails classes do not change and we fork after Rails' initialization is complete, all of our 64 processes can share the same data.
I added this and the previous paragraph after the original article has been published because Alex reminded me of this fact in the comments. Thanks to him, the singlethreaded Ruby world is all fluffy again — mostly. A multi process system still has some traditional disadvantages like a higher cost of context switching (which could be negligible for interpreted languages like Python and Ruby). Additionally, we can ignore inter-process communication costs since Rails is share-nothing.
If we do not save this memory then we might hit the memory wall: The inner loops of the interpreter will fit into the program cache. However, the interpreter needs a lot of information for each executed line of Ruby code. Simply consider all the data that has to be accessed when a simple message has to be dispatched to an object...
What could happen is that we have to access a very large set of memory positions irregularly. If this happens on every core then we might get 64 cores accessing the bus at the same time because some piece of data is missing. This data might overwrite necessary information about a class in the cache and force this data to be reloaded again... If all cores shared the same data this would not be such big an issue.
Do you think my logic is wrong and my arguments are weak? Do you see a solution or workaround? I would be thrilled to read your comments.
Updates
- The original definition of a thread was missing that a thread has a stack. Thanks, DocInverter. (2007-09-26 17:39 MEST)
- Luckily, Alex was smart enough to see what I forgot: Modern Unices do copy-on-write sharing of address spaces when forking. I corrected the article. (2007-09-26 18:05 MEST)
 Atom Feed
Atom Feed
13 comments:
Your definition of Threads is incomplete:
A thread consists of CPU registers, and the stack.
I dont have a real opinion about your content - neither pro or con, I know not enough about threading and processes - I just wanted to say that it is _refreshing_ to read a good article like yours, without the usual old attacks we can sometimes see on a mailing list.
Thanks!
When you fork a POSIX process (as it happens in Linux, BSD or Solaris), the child process and the parent process share the same code memory ... that means the Ruby interpreter is shared for example.
Forked POSIX processes also share the same memory space until you change a value in memory, and then a copy is made for the process that made the change (a simplified view, but that's more or less how it works).
For a real world example, the Apache HTTPD server also works by forking processes and the only people complaining about it are those that run Apache on top of Windows (that's why there are now 2 versions of Apache2) ... and they should complain ;)
Also, at the kernel level (talking about the Linux kernel) there is no distinction between a POSIX process and a POSIX thread.
At Evan Phoenix's presentation of Rubinius at RailsConf Europe, I'm pretty sure he mentioned memory usage of fork being a problem for MRI: a fork doubles the memory usage despite being able to share memory with the parent process. This is a drawback he has fixed in Rubinius.
Current Ruby cannot take advantage of fork and COW since the garbage collector walks the object space to mark objects> This means that you can fork and use COW memory *until* the GC is run in the child process. When that happens all the COW pages are marked dirtty so the child processes take asm uch mem as the parent.
Some research has been done (and working code produced, according to the researcher) toward making Ruby "copy-on-write friendly".
See http://izumi.plan99.net/blog/?p=54 for more info.
I love the fact that scaling in the ruby world means twitter, when it should mean BOINC.
And ruby is better at the latter than rails is at the prior. "out of the box".
Hitting the memory wall is different between different architectures. NUMA will stave off the memory wall for quite a while.
So, is it safe?
yeah checkout ruby enterprise edition
I am also analysing right now Ruby vs Python for my application. And unfortunately both are not multithreading. The Python people who develop the core (Guido) do not plan to have multithreading -- may be ever.
They keep talking about how processes can use multiple CPUs as well and that's how the system should scale.
(I am sure this is Ruby's argument as well)
The problem is for most high-performance back-office applications -- the data needs to get cached (to reduce database access). There 100s of megabytes of data that needs to be cached sometimes.
And true threading (such as in C++ and probably Erland and others) allows to share the caches.
Yes, I know there are 'process caches' such as memcached -- but to access those one needs to transfer data accross process boundaries -- which is expensive if you access cache data millions of times per hour.
So overall, it is not the interpreter's memory as much -- as the fact that Cache data cannot be shared without either interprocess communications (IPC/TCP) or duplicating cache in memory.
Intel has hinted that they are looking ahead 1000 core CPUs -- and I think there will be big push to develop applications that utilize those cores effectively.
I think that multithreading -- will be supported on language level by soon to come programming languages -- and the languages that do not support it -- will be left behind.
And when I say -- language level. I do not mean Java-like libraries that support thread. I am talking about ability to declare 'safe,shared,mutable,rw' class instances and 'deferred' and 'parallel' function -- so that the compiler and interpreter
can decide on the threading strategy on their own.
Ich schätze hoch diesen Beitrag. Es ist schwer, die guten von den schlechten manchmal zu finden, aber ich denke, Sie genagelt haben! würden Sie Ihren Blog mit mehr Informationen dagegen Aktualisierung? apotheke
Great knowledge, do anyone mind merely reference back to it wärmerückgewinnung industrie
Post a Comment